部署到 Adreno™ GPU
介绍
Adreno™ 是由高通开发并用于许多 SoC 的图形处理单元(GPU)半导体 IP 核系列。
Adreno™ GPU 可以加速复杂几何图形的渲染,在提供高性能图形和丰富的用户体验的同时拥有很低的功耗。
TVM 使用 TVM 的原生 OpenCL 后端 和 OpenCLML 后端以支持加速 Adreno™ GPU 上的深度学习。TVM 的原生 OpenCL 后端通过结合纹理内存使用和 Adreno™ 友好布局来改进 Adreno™ 。 OpenCLML 是由高通发布的 SDK ,提供了大多数深度学习运算符的内核加速库。
本指南展示以下方面的不同设计
OpenCL 后端增强
TVM 的 OpenCL 后端已被增强以利用 Adreno™ 特色功能,如
- 纹理内存使用。
- Adreno™ 友好的激活布局。
- 全新的调度以加速上述功能。
Adreno™ 的一个优势是对纹理的巧妙处理。目前,TVM 能够通过对 Adreno™ 的纹理支持获得益处。下图显示了 Adreno™ A5x 架构。
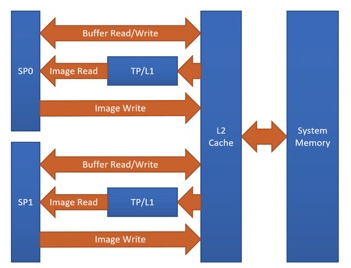
图1 用于 OpenCL Adreno™ A5x 架构的高层次概览
来源: Qualcomm Adreno™ GPU 的 OpenCL 优化和最佳实践
使用纹理的原因:
-
纹理处理器(TP)具有专用的 L1 缓存,它是只读缓存,并存储了从 2 级缓存(L2)中提取的用于纹理操作的数据(��主要原因)
-
图像边界的处理已内置。
-
支持多种图像格式和数据类型组合,支持自动格式转换
总体而言,与基于 OpenCL 缓冲区的解决方案相比,使用纹理可以获得显著的性能提升。
通常,我们将目标指定为 target="opencl" ,以生成如下所示的内核的常规OpenCL目标。
__kernel void tvmgen_default_fused_nn_conv2d_kernel0(__global float* restrict p0, __global double* restrict p1, __global float* restrict conv2d_nhwc) {
// body..
上述 OpenCL 内核定义有 __global float* 类型指针,它们实质上是 OpenCL buffer 对象。
通过修改目标定义为 target="opencl -device=adreno" 启用基于纹理的增强后,我们可以看到生成的内核使用纹理支持的 OpenCL 图像对象,如下所示。
__kernel void tvmgen_default_fused_nn_conv2d_kernel0(__write_only image2d_t pad_temp_global_texture, __read_only image2d_t p0) {
// body..
image2d_t 是内置的 OpenCL 类型,用于表示二维图像对象并提供几个附加功能。 当我们使用 image2d_t 时,我们一次读取 4个元素 可以更有效地利用硬件。
有关生成和检查内核源的更多详细信息,请参阅高级用法。
关于 OpenCLML
OpenCLML 是高通发布的 SDK ,提供了更快的深度学习运算符。这些运算符作为标准 OpenCL 规范的扩展 cl_qcom_ml_ops 公开。有关更多详细信息,请参见 Accelerate your models with our OpenCL ML SDK 。
OpenCLML 已集成到 TVM ,作为 BYOC 解决方案。 OpenCLML 运算符可以使用相同的上下文,并可以加入到同样被原生 OpenCL 使用的命令队列中。我们利用了这一点避免在回退到原生 OpenCL 时的上下文切换。
Adreno™ 下的 TVM
本节提供有关构建和部署模型到 Adreno™ 目标机的方法说明。 Adreno™ 是通过 ADB 连接与主机连接的远程目标。在这里部署已编译的模型需要在主机和目标上使用一些工具。
TVM 提供了简单的、用户友好的命令行工具以及专为开发者设计的 Python API 接口,可用于各种步骤,如自动调整、构建和部署。
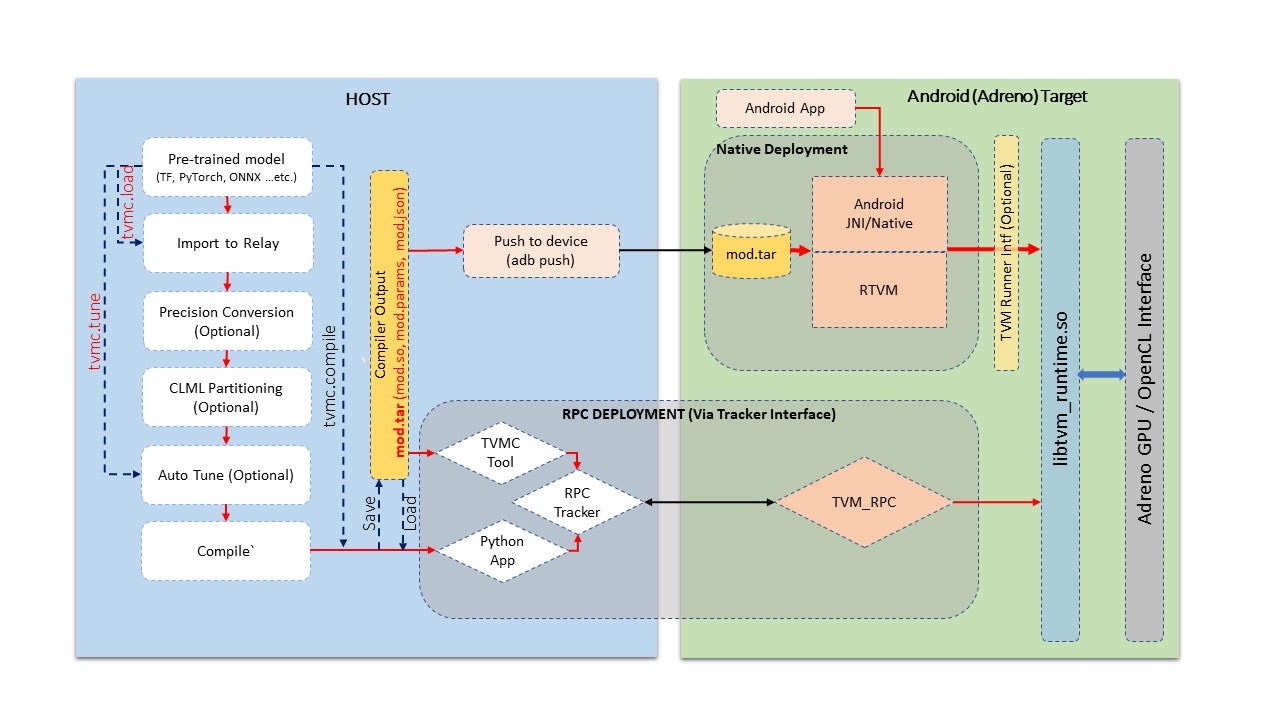 图2 Adreno 设备的构建和部署流水线
图2 Adreno 设备的构建和部署流水线
上图展示了以下各个阶段的通用流程:
-
导入模型:在此阶段,我们从知名框架(如 TensorFlow、PyTorch、ONNX 等)导入模型。该阶段将给定的模型转换为 TVM 的 relay 模块格式。或者也可以通过使用 TVM 的操作库手动构建 relay 模块。此处生成的 TVM 模块的是独立于图的表示形式的目标。
-
自动调整:在此阶段,我们调整特定于目标的 TVM 生成的内核。自动调整过程需要目标设备的有效性,在如 Android 设备上的 Adreno™ 这样的远程目标中,我们使用 RPC 设置进行通信。本指南的后续部分将详细介绍 Android 设备的 RPC 设置。自动调整不是模型编译的必需步骤,但对于获得 TVM 生成的内核的最佳性能是必要的。
-
编译:在此阶段,我们为特定目标编译模型。鉴于我们在前一阶段自动调整了模块, TVM 编译利用调整日志以生成性能最佳的内核。 TVM 编译进程中产生包含内核的共享库、以 json 格式定义的图和以 TVM 特定格式的二进制参数文件。
-
部署(或测试运行)到目标:在此阶段,我们在目标上运行 TVM 编译输出。部署可以从 Python 环境中使用 RPC 设置。也可以使用 TVM 的本地工具进行,该工具可以为 Android 进行本地二进制交叉编译。在此阶段,我们可以在 Android 目标上运行已编译的模型,并对输出的正确性和性能方面进行单元测试。
-
应用集成:本阶段涉及将 TVM 编译的模型集成到应用程序中。我们在这里讨论如何从 Android(cpp 本地环境或 JNI)中设置输入和获取输出的 TVM 运行时接口。
-
高级用法:本部分涵盖了高级用户感兴趣的主题,如查看生成的源代码、更改模块的精度等。
此教程以下各节将涵盖上述内容。
自动开发环境设置
TVM 提供了一个预定义的 Docker 容器环境,其中包含了所有入门所需的先决条件。如果您想要更多地控制依赖关系,请参考手动环境设置。
对于 Docker 设置,先决条件只是主机上有 Docker 工具。
以下命令可以构建 Adreno 的 Docker 镜像:
./docker/build.sh ci_adreno
docker tag tvm.ci_adreno ci_adreno
现在,我们可以使用以下命令构建主机和目标工具:
./tests/scripts/ci.py adreno -i
要使用 OpenCLML SDK 构建TVM,在构建时需要导出 OpenCLML SDK,如下所示:
export ADRENO_OPENCL=<OpenCLML SDK路径>
./tests/scripts/ci.py adreno -i
成功编译后,您将进入 Docker shell。构建将生成两个文件夹:
build-adreno:主机端TVM编译器构建。build-adreno-target:包含 Android 目标组件。- libtvm_runtime.so:TVM 运行时库
- tvm_rpc:rpc 运行时环境工具
- rtvm:独立的原生工具
在使用Docker环境时, Android 设备与主机共享,所以在主机上需要安装 ADB 版本为 1.0.41 ,因为 Docker 使用相同的版本。
您还可以在 Docker 环境中检查 ADB 设备的可用性:
user@ci-adreno-fpeqs:~$ adb devices
List of devices attached
aaaabbbb device
ccccdddd device
手动开发环境设置
手动构建过程需要构建主机和目标组件。
以下命令将配置主机编译:
mkdir -p build
cd build
cp ../cmake/config.cmake .
# 启用 RPC 功能以与远程设备通信。
echo set\(USE_RPC ON\) >> config.cmake
# 我们在主机(x86)上使用图执行器验证模型。
echo set\(USE_GRAPH_EXECUTOR ON\) >> config.cmake
# 启用溢出时的回溯以获取更多调试信息。
echo set\(USE_LIBBACKTRACE AUTO\) >> config.cmake
# 目标主机将是 llvm。
echo set\(USE_LLVM ON\) >> config.cmake
此外,我们可以推送以下配置条目,以使用 OpenCLML 支持进行编译:
export ADRENO_OPENCL=<OpenCLML SDK路径>
echo set\(USE_CLML ${ADRENO_OPENCL}\) >> config.cmake
现在我们可以像下面这样构建:
cmake ..
make
最后,我们可以导出 Python 路径:
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
python3 -c "import tvm" # 验证tvm Python包
现在,我们可以使用以下配置来配置和构建目标组件。目标构建需要安装 Android NDK。
- 在此处阅读有关 Android NDK 安装 的文档:https://developer.android.com/ndk
- 要获取 adb 工具的访问权限,您可以在此处查看 Android Debug Bridge 安装 :https://developer.android.com/studio/command-line/adb
mkdir -p build-adreno
cd build-adreno
cp ../cmake/config.cmake .
# 启用 OpenCL 后端。
echo set\(USE_OPENCL ON\) >> config.cmake
# 启用 RPC 功能。
echo set\(USE_RPC ON\) >> config.cmake
# 构建在目标设备上运行的 tvm_rpc 工具。
echo set\(USE_CPP_RPC ON\) >> config.cmake
# 构建本机 rtvm 部署工具。
echo set\(USE_CPP_RTVM ON\) >> config.cmake
# 我们在像 Android 这样的设备上使用图执行器。
echo set\(USE_GRAPH_EXECUTOR ON\) >> config.cmake
# 在可能的情况下启用回溯。
echo set\(USE_LIBBACKTRACE AUTO\) >> config.cmake
# Adreno 支持 OpenCL 分配的32位对齐而不是64位。
echo set\(USE_KALLOC_ALIGNMENT 32\) >> config.cmake
# Android 构建相关定义。
echo set\(ANDROID_ABI arm64-v8a\) >> config.cmake
echo set\(ANDROID_PLATFORM android-28\) >> config.cmake
echo set\(MACHINE_NAME aarch64-linux-gnu\) >> config.cmake
此外,我们可以推送以下��配置以使用 OpenCLML 支持进行编译:
export ADRENO_OPENCL=<OpenCLML SDK路径>
echo set\(USE_CLML "${ADRENO_OPENCL}"\) >> config.cmake
echo set\(USE_CLML_GRAPH_EXECUTOR "${ADRENO_OPENCL}"\) >> config.cmake
对于 Android 目标构建,ANDROID_NDK_HOME 是一个依赖项,我们应该在环境变量中设置相同的依赖项。以下命令将构建 Adreno™ 目标组件:
cmake -DCMAKE_TOOLCHAIN_FILE="${ANDROID_NDK_HOME}/build/cmake/android.toolchain.cmake" \
-DANDROID_ABI=arm64-v8a \
-DANDROID_PLATFORM=android-28 \
-DCMAKE_SYSTEM_VERSION=1 \
-DCMAKE_FIND_ROOT_PATH="${ADRENO_OPENCL}" \
-DCMAKE_FIND_ROOT_PATH_MODE_PROGRAM=NEVER \
-DCMAKE_FIND_ROOT_PATH_MODE_LIBRARY=ONLY \
-DCMAKE_CXX_COMPILER="${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang++" \
-DCMAKE_C_COMPILER="${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang" \
-DMACHINE_NAME="aarch64-linux-gnu" ..
make tvm_runtime tvm_rpc rtvm
RPC 设置
RPC 设置允许通过 TCP/IP 网络接口访问远程目标。RPC 设置对于自动调整阶段是必不可少的,因为调整涉及在真实设备上运行自动生成的内核,并通过使用机器学习方法对其进行优化。请参考 使用模板和 AutoTVM 进行自动调整 以获取有关 AutoTVM 的详细信息。
RPC 设置也可用于通过 python 接口或来自主机设备的 tvmc 工具将已编译的模型部署到远程设备。
RPC 设置有多个组件,如下所示。
TVM Tracker: TVM Tracker 是主机端的守护程序,管理远程设备并为主机端应用程序提供服务。应用程序可以连接到此跟踪器并获取远程设备句柄以进行通信。
TVM RPC: TVM RPC 是在远程设备上运行的本地应用程序(本情况下是 Android ),并向在主机上运行的 TVM Tracker 注册自身。
因此,对于基于 RPC 的设置,我们将在主机和目标设备上运行上述组件。以下部分解释了如何手动设置相同的内容,以及如何在使用自动化工具的 Docker 环境中设置相同的内容。
**自动化 RPC 设置:**此处,我们将解释如何在 Docker 环境中设置 RPC 。
以下命令在 Docker 环境中启动 tracker,其中 tracker 监听端口 9190。
./tests/scripts/ci.py adreno -i # 在 anreno docker 上启动一个新的 shell
source tests/scripts/setup-adreno-env.sh -e tracker -p 9190
现在,以下命令可以在具有 ID abcdefgh 的远程 Android 设备上运行 TVM RPC 。
./tests/scripts/ci.py adreno -i # 在adreno docker上启动一个新的shell。
source tests/scripts/setup-adreno-env.sh -e device -p 9190 -d abcdefgh
此外,以下命令可用于在任何其他 Docker 终端上查询 RPC 设置详细信息。
./tests/scripts/ci.py adreno -i # 在 adreno docker 上启动一个新的 shell。
source tests/scripts/setup-adreno-env.sh -e query -p 9190
**手动 RPC 设置:**请参阅教程 在 Adreno 上部署模型 了解手动 RPC 环境设置。
这些 RPC 设置完成后,我们在主机 127.0.0.1(rpc-tracker)上拥有 rpc-tracker,端口 9190 (rpc-port)可用。
.. _commandline_interface:
命令行工具
此处我们使用命令行工具描述整个编译进程。 TVM 具有命令行实用程序 tvmc,用于执行模型导入、自动调整、编译和 rpc 部署。 tvmc 有许多选项可供探索和尝试。
**模型导入和调整:**使用以下命令从任何框架导入模型并对其进行自动调整。此处我们使用来自 Keras 的模型,它使用 RPC 设置进行调整,并最终生成调整日志文件 keras-resnet50.log 。
python3 -m tvm.driver.tvmc tune --target="opencl -device=adreno" \
--target-host="llvm -mtriple=aarch64-linux-gnu" \
resnet50.h5 -o \
keras-resnet50.log \
--early-stopping 0 --repeat 30 --rpc-key android \
--rpc-tracker 127.0.0.1:9190 --trials 1024 \
--tuning-records keras-resnet50-records.log --tuner xgb
模型编译:
使用以下命令编译模型并生成TVM编译器输出。
python3 -m tvm.driver.tvmc compile \
--cross-compiler ${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang \
--target="opencl, llvm" --target-llvm-mtriple aarch64-linux-gnu --target-opencl-device adreno \
--tuning-records keras-resnet50.log -o keras-resnet50.tar resnet50.h5
在启用 OpenCLML 卸载时,我们需要如下添加目标 clml 。调整日志对于 OpenCLML 卸载同样有效,因为 OpenCL 路径是没有经过 OpenCLML 路径的任何运算符的回退选项。调整日志将用于这类运算符。
python3 -m tvm.driver.tvmc compile \
--cross-compiler ${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang \
--target="opencl, clml, llvm" --target-llvm-mtriple aarch64-linux-gnu --target-opencl-device adreno \
--tuning-records keras-resnet50.log -o keras-resnet50.tar resnet50.h5
在成功编译后,上述命令会产生 keras-resnet50.tar 。这是一个压缩存档,包含有 kernel shared lib( mod.so )、graph json( mod.json )和参数二进制( mod.params )。
在目标上部署和运行:
可以通过 RPC 方式和本地部署方式实现在 Android 目标上运行编译后的模型。
我们可以使用下面的 tvmc 命令通过 RPC 基础设置在远程目标上部署。
python3 -m tvm.driver.tvmc run --device="cl" keras-resnet50.tar \
--rpc-key android --rpc-tracker 127.0.0.1:9190 --print-time
基于运行的 tvmc 提供了更多选项,用于以各种模式(如 fill 、 random 等)初始化输入。
基于部署的 tvmc 通常是通过 RPC 设置从远程主机快速验证在目标上编译的模型的一种方式。
通常,生产环境使用原生部署环境,如 Android JNI 或 CPP 原生环境。此处我们需要使用交叉编译的 tvm_runtime 接口来部署 tvm 编译输出,即 TVMPackage 。
TVM 有一个名为 rtvm 的独立工具,用于在 ADB shell 上本地部署和运行模型。构建过程会在 build-adreno-target 下生成此工具。有关有关此工具的更多详细信息,请参阅 rtvm 。
在将其集成到现有 Android 应用程序中时, TVM 有多种选择。对于 JNI 或 CPP 原生,我们可以使用 C Runtime API 。
您还可以参考 rtvm 的简化接口 TVMRunner 。
Python 接口
该节解释如何使用 Python 接口导入、自动调整、编译和运行模型的过程。 TVM 通过 tvmc 抽象提供高级接口,以及低级的 Relay API 。我们将详细讨论这两者。
TVMC 接口:
在使用 tvmc Python接口时,我们首先加载一个生成 TVMCModel 的模型。 TVMCModel 将用于自动调整以生成调整缓存。编译进程使用 TVMCModel 和调整缓存(可选)来生成 TVMCPackage 。现在 TVMCPackage 将保存到文件系统,或者可以用于部署和在目标设备上运行。
请参考相应的教程如何使用 TVMC 在 Adreno 上部署预训练模型。
保存的 TVMCPackage 也可以用于使用 rtvm 工具进行原生部署。
此外,请参考 使用 TVMC 编译和优化模型 文档,了解有关 API 接口的更多详细信息。
Relay 接口:
Relay API 接口提供了对 TVM 编译器接口的低级 API 访问。与 tvmc 接口类似,Relay API 接口提供了各种前端 API,用于将模型转换为 Relay Module。Relay Module 将用于所有种类的转换,如精度转换、CLML 卸载和其他自定义转换(如果有)。生成的 Module 也将用于自动调整。最��后,我们使用 relay.build API 生成库模块。从这个库模块,我们可以导出编译产物,如模块共享库(mod.so)、参数(mod.params)和 json 图(mod.json)。这个库模块将用于创建图形运行时以在目标设备上部署和运行。
请参考教程如何在 Adreno 上部署预训练模型,其中逐步解释了相同的内容。
此外,TVM 还通过 TVM4J 支持 Java 接口。
应用程序集成
TVM 编译输出以模块共享库(mod.so)、图形 json (mod.json)和参数(mod.params)的形式表示。 TVMPackage 的存档表示也包含相同的内容。
通常对于任何 Android 应用程序集成来说,基于 CPP/C 的接口就足够了。
TVM 原生地公开了 c_runtime_api,用于加载 TVM 编译的模块并运行相同的模块。
或者,用户还可以参考 cpp_rtvm 中的 TVMRunner 接口,以获得相同的进一步简化的版本。
.. _advanced_usage:
高级用法
本节详细介绍在 TVM 上 使用 Adreno™ 目标机时的一些高级用法和其他信息。
生成源码检查
除了标准的 tvm 编译产物(kernel 库 mod.so 、图形 mod.json 和参数 mod.params)之外,我们还可以从 lib handle 生成 opencl kernel 源码、clml 卸载图等。TVM 编译的输出被组织为一个 TVM 模块,其中包含许多其他导入的 TVM 模块。
下面的代码段可以将 CLML子 图以 json 格式转储。
# 查找 "clml" 类型的导入模块。
clml_modules = list(filter(lambda mod: mod.type_key == "clml", lib.get_lib().imported_modules))
# 循环遍历所有 clml 子图并转储以 json 格式的 CLML 子图。
for cmod in clml_modules:
print("CLML Src:", cmod.get_source())
类似地,下面的代码段可以从编译的 TVM 模块中提取 opencl
# 类似地,我们可以转存开放的内核源码如下所示
# 寻找 "opencl" 类型模块导入.
opencl_modules = list(filter(lambda mod: mod.type_key == "opencl", lib.get_lib().imported_modules))
# 现在为每一个 Open CL 的目标子图转储内核源码
for omod in opencl_modules:
print("OpenCL Src:", omod.get_source())
精度
选择特定工作负载的正确精度可以极大地提高解决方案的效率,将精度和速度的初始平衡转移到问题的首要一侧。
我们可以选择 float16,float16_acc32(混合精度),float32(标准)。
Float16
为了充分利用 GPU 硬件功能并利用半精度计算和内存管理的优势,我们可以将具有浮点运算的原始模型转换为使用半精度运算的模型。选择较低的精度将积极地影响模型的性能,但也可能导致模型精度下降。
要执行转换,您需要在任何一个前端生成 Relay 模块的同时调用 Adreno 特定的转换 API 。
from tvm.driver.tvmc.transform import apply_graph_transforms
mod = apply_graph_transforms(
mod,
{
"mixed_precision": True,
"mixed_precision_ops": ["nn.conv2d", "nn.dense"],
"mixed_precision_calculation_type": "float16",
"mixed_precision_acc_type": "float16",
},
)
tvm.driver.tvmc.transform.apply_graph_transforms 是对 ToMixedPrecision 传递的简化 API ,为了获取所需的精度。
然后我们可以以任意方便的方式编译我们的模型:
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(
mod, target_host=target_host, target=target, params=params
)
在使用 tvmc Python接口时,下面的参数启用到 float16 的精度转换:
mixed_precision = True,
mixed_precision_ops = ["nn.conv2d", "nn.dense"],
mixed_precision_calculation_type = "float16",
mixed_precision_acc_type = "float16"
同样,tvmc 命令行接口选项有以下列出的选项:
--mixed-precision
--mixed-precision-ops nn.conv2d nn.dense
--mixed-precision-calculation-type float16
--mixed-precision-acc-type float16
float16_acc32 (混合精度)
ToMixedPrecision 过程遍历网络并将网络拆分为处理 float 或 float16 数据类型的操作簇。这些簇由三种类型的操作定义:
- 总是转换为 float16 数据类型的操作
- 如果后面跟着转换簇,可以转换的操作
- 从不转换为 float16 数据类型的操作
此列�表在 ToMixedPrecision 的实现 relay/transform/mixed_precision.py 中定义,用户可以覆盖。
ToMixedPrecision 方法是将 FP32 的 Relay 图转换为 FP16 版本(使用 FP16 或 FP32 累积数据类型)的过程。进行此转换对于减小模型大小很有用,因为它将权重的期望大小减半(FP16_acc16情况)。
ToMixedPrecision 过程的使用简化为以下代码:
from tvm.driver.tvmc.transform import apply_graph_transforms
mod = apply_graph_transforms(
mod,
{
"mixed_precision": True,
"mixed_precision_ops": ["nn.conv2d", "nn.dense"],
"mixed_precision_calculation_type": "float16",
"mixed_precision_acc_type": "float32",
},
)
tvm.driver.tvmc.transform.apply_graph_transforms 是对 ToMixedPrecision 过程的简化 API ,以获取所需的精度。
然后我们可以以任何方便的方式编译我们的模型:
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(
mod, target_host=target_host, target=target, params=params
)
在使用 tvmc Python 接口时,下面的参数启用到 float16_acc32 的精度转换:
mixed_precision = True,
mixed_precision_ops = ["nn.conv2d", "nn.dense"],
mixed_precision_calculation_type = "float16",
mixed_precision_acc_type = "float32"
同样, tvmc 命令行接口选项有以下选项:
--mixed-precision
--mixed-precision-ops nn.conv2d nn.dense
--mixed-precision-calculation-type float16
--mixed-precision-acc-type float32